
Powerful Models on a Budget: Combining DoReMi Optimization with Synthetic Data
In the race to build robust AI models, size isn't everything.

Introduction
As giants like OpenAI and Anthropic pave the way for massive models that are poised to transform the AI scene, a burning question arises: What does the future hold for the broader AI community, especially for those outside major research labs?
Our focus remains on finding answers not in sheer model size but in tapping into the benefits of compactness. Two emerging strategies show potential for vastly improved training efficiency and flexibility: DoReMi's Domain Reweighting with Minimax Optimization and various advances in synthetic data-driven training methods.
In this piece, we delve into the first open-source efforts to integrate these approaches and discuss our latest discoveries.
Reviewing Recent Results
DoReMi
The genius of DoReMi lies in its innovation around pretraining data domains. It rethinks how models are trained, emphasizing the significant impact of mixture proportions, such as those from Wikipedia, books, and web text, on overall performance. In previous works, authors used intuition and informal experimentation to determine the weighting across these different splits. DoReMi proposes a more scientific method by training smaller proxy models with group distributionally robust optimization (Group DRO) to select the weightings over these domains. The result? Robust domain weights crafted without any prior knowledge of downstream tasks. These weights then guide the resampling of datasets to train even more robust, larger models. For instance, in recent experiments, a 280M-parameter proxy model powered by DoReMi was leveraged to optimize the training of an 8B-parameter model, achieving impressive results in efficiency and accuracy.
Synthetic Data
On the other hand, recent results have shown the great promise of synthetic data in training LLMs. Building upon foundational work like "TinyStories" and "Phi-1," the "Textbooks Are All You Need" philosophy is championed. We reviewed much of these recent breakthroughs in a previous substack, “If you are GPU-Poor, then you should be paying attention to synthetic data & small LLMs”.
Phi's recent brainchild, the "phi-1.5" model, epitomizes the power of small models, boasting capabilities potentially akin to LLMs five times its size and trained with much more compute. Harnessing the might of "textbook quality" synthetic data, Phi-1.5 shines in natural language tasks and even complex reasoning challenges, from grade-school math to elementary coding. However, the data used to train Phi was not released, and so precise replication of the synthetic data used to generate these results has become an ongoing question.
Challenges with synthetic data
Synthetic data's potency lies in its ability to quickly and controllably simulate real-world information, with a succinct vocab, unified tone, and targeted distribution. However, the art of generating this data is fraught with challenges. A synthetic dataset can be structured in myriad ways, echoing the instructive tone of a manual, the reflective nature of introspective thinking, or the straightforward approach of a textbook.
Furthermore, the range in difficulty levels of synthetic data is vast. One could design a dataset that spans elementary concepts to advanced theories, or one that dives deep into a niche area of knowledge. Deciding on the ideal distribution is non-trivial, especially when considering the vast landscape of potential learning tasks an AI model may encounter.
Ongoing Research Efforts
Currently, we are forming a collaboration that aims to replicate the results obtained by the phi-1.5 model. Further, we are planning to continue carrying out research on synthetic data in an open source setting.
We are generating synthetic data with the SciPhi framework, as well as the textbook quality framework. We have access to a modest amount of computation power (8-16x A100s at any given moment) and are doing our pre-training within a customized standalone framework, SmolTrainer. The OpenPhi collaboration can be found on HuggingFace here.
DoReMi's Potential Role in Synthetic Data Generation
Given that DoReMi is a technique for calculating the optimal mixture proportions from diverse data domains, it offers a unique solution to the challenges presented in determining the optimal generation of synthetic data. I.e. if DoReMi can approximate the the ideal blend of real-world data sources for training a model, it's plausible to believe it could guide the generation of synthetic data as well
By gauging the importance of different synthetic datasets, DoReMi could theoretically provide the approximate optimal weights to apply when scaling out synthetic sample generation. To the best of the author’s knowledge, the combination of these two techniques has not yet been attempted - our first goal was to attempt a simplified version of this idea and to study the results.
Which model & datasets?
To simplify this approach into a tractable first pass we decided to train small models on different splits of publicly available synthetic datasets.
Across all experiments we use EleutherAI’s pythia-410m parameter model with the Mistral 7b tokenizer, which results in a 365m parameter model.
Our first stop after selecting an architecture was to obtain synthetic data from HuggingFace. We selected a diverse array of 21 datasets. Our initial goal was to pre-train our selected architecture from scratch to near-convergence on various splits of these selected data sources.
We trained the selected architecture on ~3bn tokens with the following data splits:
sciphi-combine (1+2)
programming-books-sciphi-combine (3+4+5)
programming-books-sciphi-orca-combine (5+6)
global_combine_v0 (7+8+others)
global_combine_v1 (9+others)
*Note, synthetic datasets 2 & 4 make use of derivatives of the LLama2 models in their creation process, which therefore implies that further downstream work is also a derivative work of Llama2.
Further, for the global combine dataset(s) we added additional training rounds to better study the the convergence behavior.
Interpreting the Training Results:
Each training run has its own characteristic loss curve, because the dataset varies across experiments. For example, here are the loss curves for the model trained on Tiny Textbooks

We can see that we trained well past convergence for this model, but not to the point of severe overfitting.
Our first instinct was to run benchmark evaluations on the output models in order to make general comparisons. However, we quickly realized that with small models that have undergone light training, the benchmark results are noisy and inconclusive. We believe this is why the authors of DoReMi chose to go with perplexity as an evaluation metric, and we have thus followed suit.
Below is a comparison of perplexity measurements made across this broad swath of synthetic datasets and real datasets that are publicly available
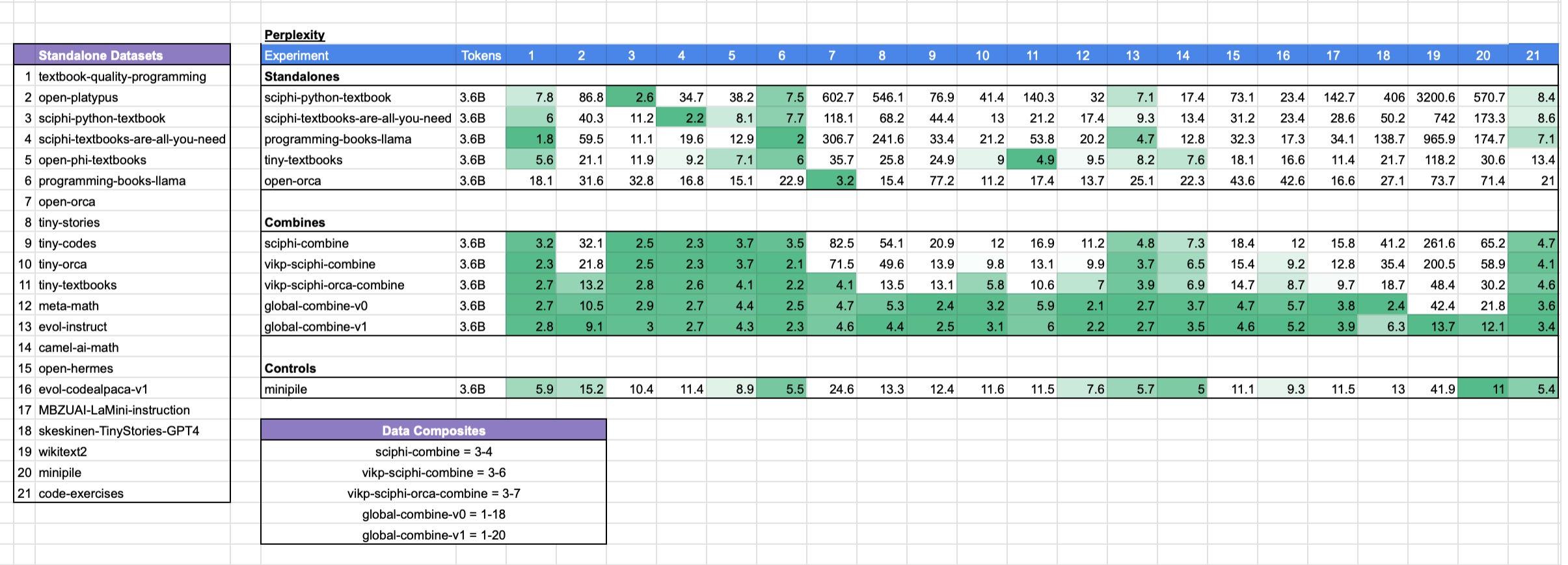
Some tentative observations from the above table
Models trained on one narrow synthetic dataset have high perplexity on wiki/pile datasets (to be expected).
programming-books-llama performs well on programming data (its own data, tiny-codes, evol-instruct, and code-exercises), but performs badly on non-coding data.
The sciphi-combine model does quite well for the number of tokens in the merged dataset (700m) - beating all other similar sized datasets in median perplexity across the full range of considered datasets.
The minipile model comes close to synthetic-only datasets in terms of perplexity performance across the broad range of datasets.
The more diverse the combination dataset, the better the average performance across diverse datasets, with the global-combine datasets having the most promising results.
It’s not yet 100% clear whether or not introducing wikitext + minipile helps or hurts.
Notes on how to extend these basic studies further
Match dataset sizes in tokens to control for # of tokens - e.g. the datasets above all have different sizes, which introduces noise and uncertainty into our analysis.
Consider measuring scaling vs N tokens as well as N params, since both are now controllable parameters.
Target Next Steps:
At this stage, we have only done a very crude approximation of the work shown by the DoReMi paper. We have demonstrated that splitting datasets hurts performance and that downstream perplexity is generally improved with dataset diversification. We have not yet shown how re-sampling the datasets can extend this result further. To do so, we will need to identify non-unit weights to apply to various datasets, in order to optimize the training sample composition. This should include both the subdomains in the minipile and the synthetic datasets that are included.
Another reasonable next step may be to run a training run with the available data on the full 1.3bn parameter model. A classifier could be introduced to select only high quality pile or coding related data, which can then be mixed with the synthetic data. The outcome of this experiment could quite likely be competitive with the original phi-1 result, giving us confidence as we move to scale up our synthetic data generation pipeline.
Conclusion
As the AI landscape evolves, the quest for efficient and flexible training mechanisms remains paramount. Both the innovative DoReMi domain reweighting approach and the expanding use of synthetic data represent crucial advancements in this domain.
Our exploratory efforts indicate that integrating these methodologies can lead to promising outcomes, particularly in optimizing data domain proportions for enhanced training. While our research is in its early stages, we are optimistic about the upcoming results. As we venture further into this realm, fostering an open-source, collaborative approach will be crucial to unlocking the vast potential these strategies present.
Interested in Collaborating:
We eagerly AI enthusiasts and experts alike to join us on this rewarding journey towards creating more efficient and robust AI models for the future.
Join the Discord here or reach out to me for more details.
Hi Owen, thanks for you work. It's really helpful 🙌 🙌
I'm trying to run DOREMI on the entire 21 dataset to get the weight to create global_combine_v1.
But I have some cuda version problems. as I understand doremi is just for detecting weights of datasto combine. Can you share the doremi weights what it was for global_combine_v1? In order to prevent Doremi from rerunning
alternatively, if you have global_combine_v1 already, it would be great to share, Thanks
I am also following the same thoughts and was looking at a way to use Karpathy's llama2c instead of Pythia and the synthetic datasets (of high quality) to have 100MB-300 MB task specific models.
Did you publish your pipeline?